Abstract
Embodied vision-based real-world systems, such as mobile robots, require a careful balance between energy consumption, compute latency, and safety constraints to optimize operation across dynamic tasks and contexts. As local computation tends to be restricted, offloading the computation, ie, to a remote server, can save local resources while providing access to high-quality predictions from powerful and large models. However, the resulting communication and latency overhead has led to limited usability of cloud models in dynamic, safety-critical, real-time settings. To effectively address this trade-off, we introduce UniLCD, a novel hybrid inference framework for enabling flexible local-cloud collaboration. By efficiently optimizing a flexible routing module via reinforcement learning and a suitable multi-task objective, UniLCD is specifically designed to support the multiple constraints of safety-critical end-to-end mobile systems. We validate the proposed approach using a challenging, crowded navigation task requiring frequent and timely switching between local and cloud operations. UniLCD demonstrates improved overall performance and efficiency, by over 35% compared to state-of-the-art baselines based on various split computing and early exit strategies.
Motivation
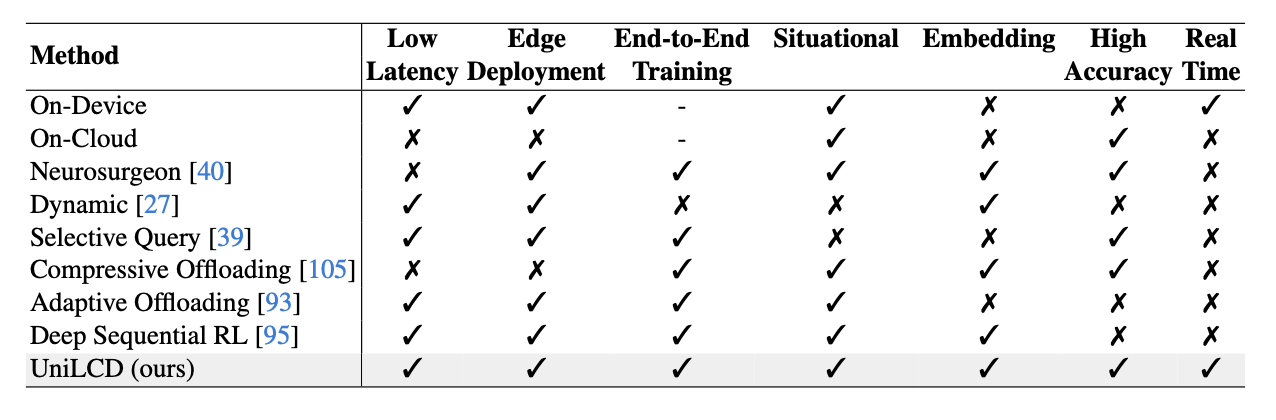
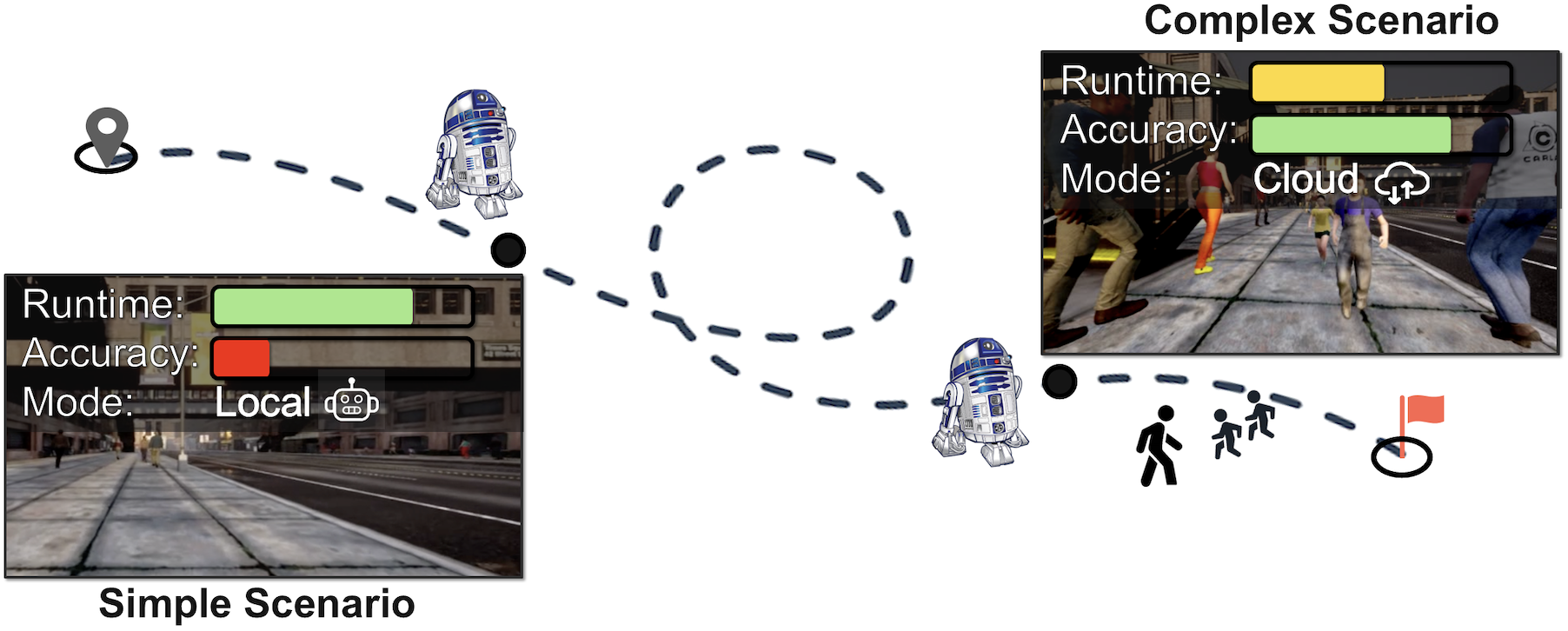
Our motivation is to solve the research question: How to realize robust vision-based systems that can be flexibly optimized for both safety and real-time efficiency while operating in dynamic real-world settings? Processing data through remote cloud servers can deliver high-quality model predictions but introduces latency that is unsuitable for dynamic real-world systems; hence, safety-critical and mobile systems often rely on local processing with model pruning and quantization to meet real-time constraints, though this can degrade accuracy and impact decision-making. Our algorithm proposes a generalized paradigm for situation-specific cloud-local collaboration that balances energy cost and accuracy, optimizing for latency, efficiency, and safety while supporting sustainable system operation.
Method
- Cloud and Local Policies: We use a standard imitation learning with L1 error minimization approach to train navigation policies offline by collecting a diverse dataset from CARLA, featuring complex routes and weather conditions. Both local and cloud policies are developed with shared visual features and goal-conditional modules, where the local policy uses a smaller, optimized version of the pre-trained cloud policy, reducing computational costs.
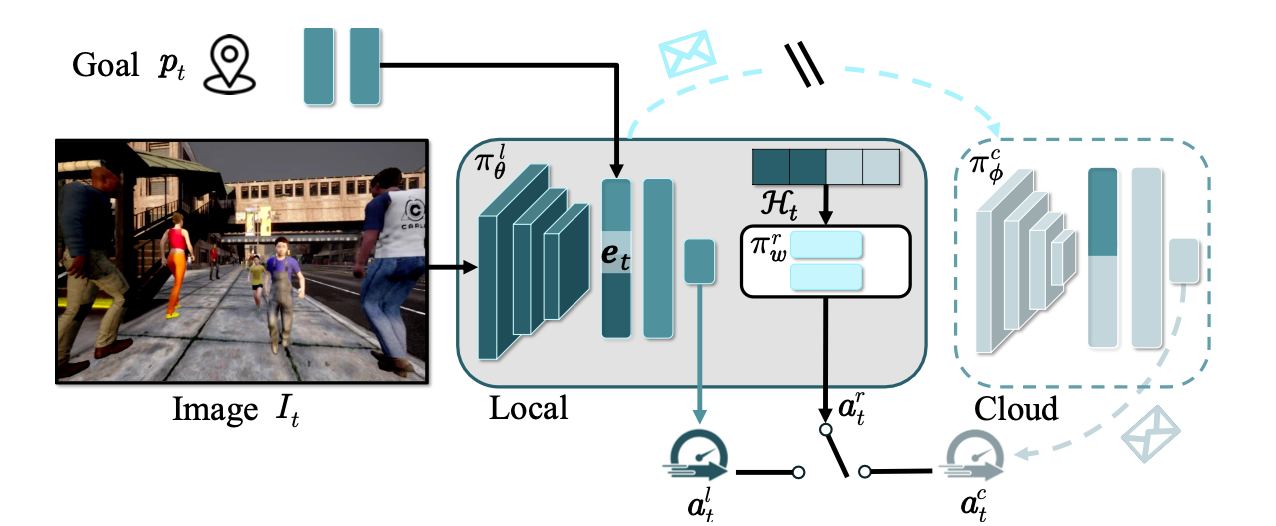
- Routing Policy : We introduce a routing policy that optimally balances local and cloud computing resources using Proximal Policy Optimization (PPO), where the state space includes image embeddings and action history, and the action space is binary for selecting between local or cloud navigation. Our reward function integrates geodesic alignment, speed, energy efficiency, action clipping, and collision penalties to improve optimization and task performance, with specific penalties for sub-optimal actions and collisions to ensure effective and safe navigation.
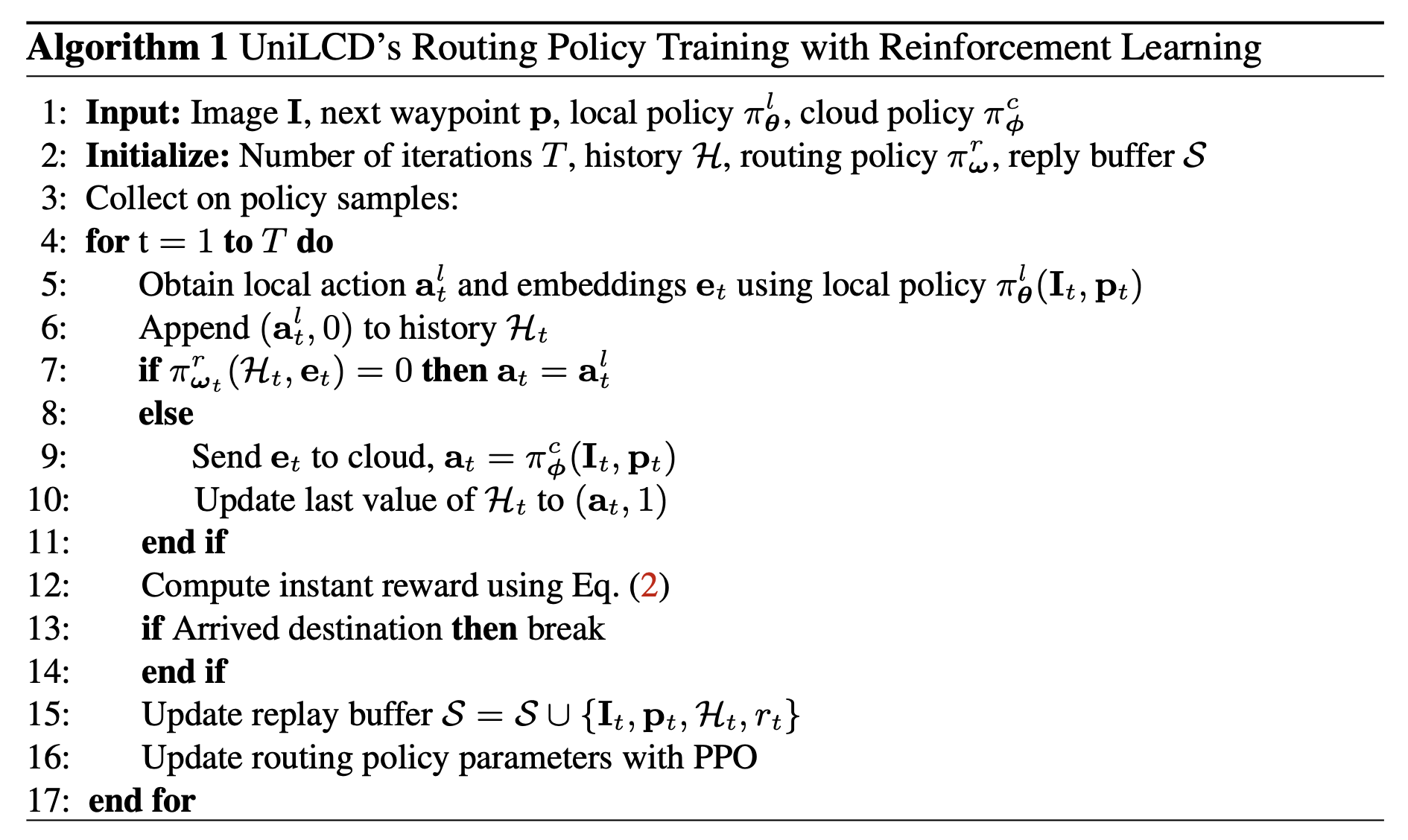
UniLCD Algorithm Diagram
The architecture diagram of our algorithm UniLCD is shown that features a situational routing module that utilizes current embeddings and a history of previous actions. Local actions are predicted by a pre-trained lightweight model for efficient deployment on mobile systems, while a sample-efficient routing module, trained via reinforcement learning, decides whether to execute local actions or transmit the scene embeddings to a more accurate but computationally intensive cloud server model.
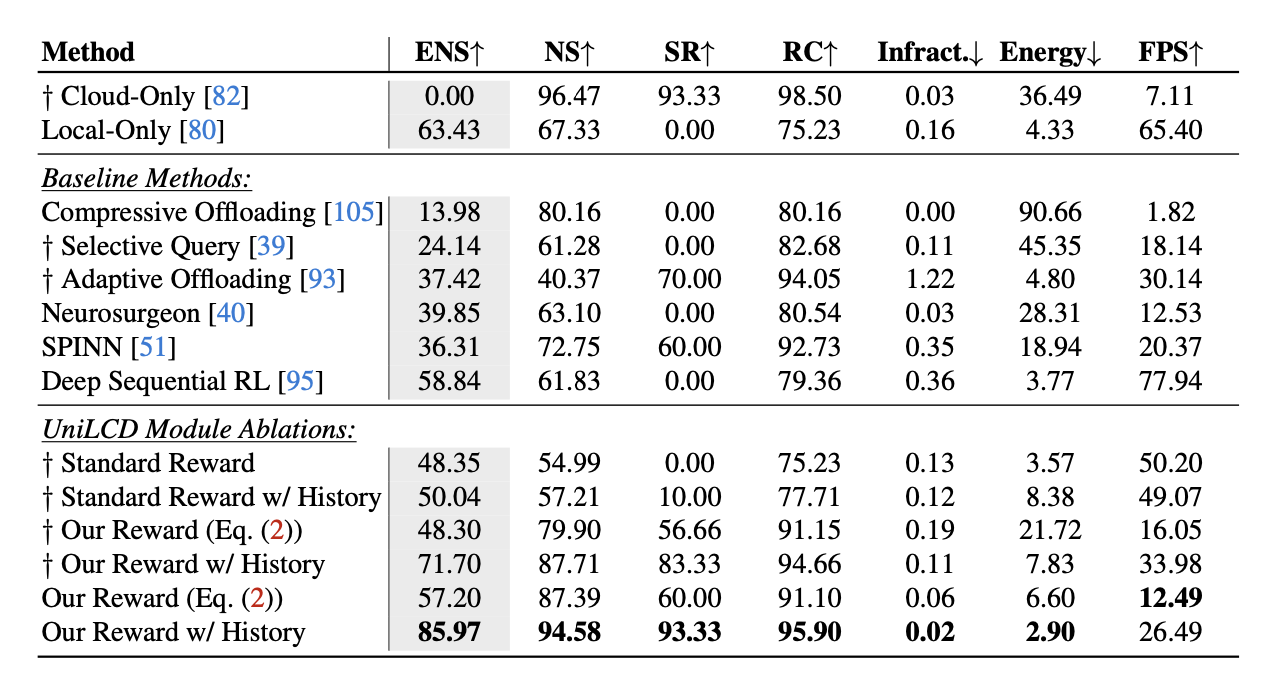
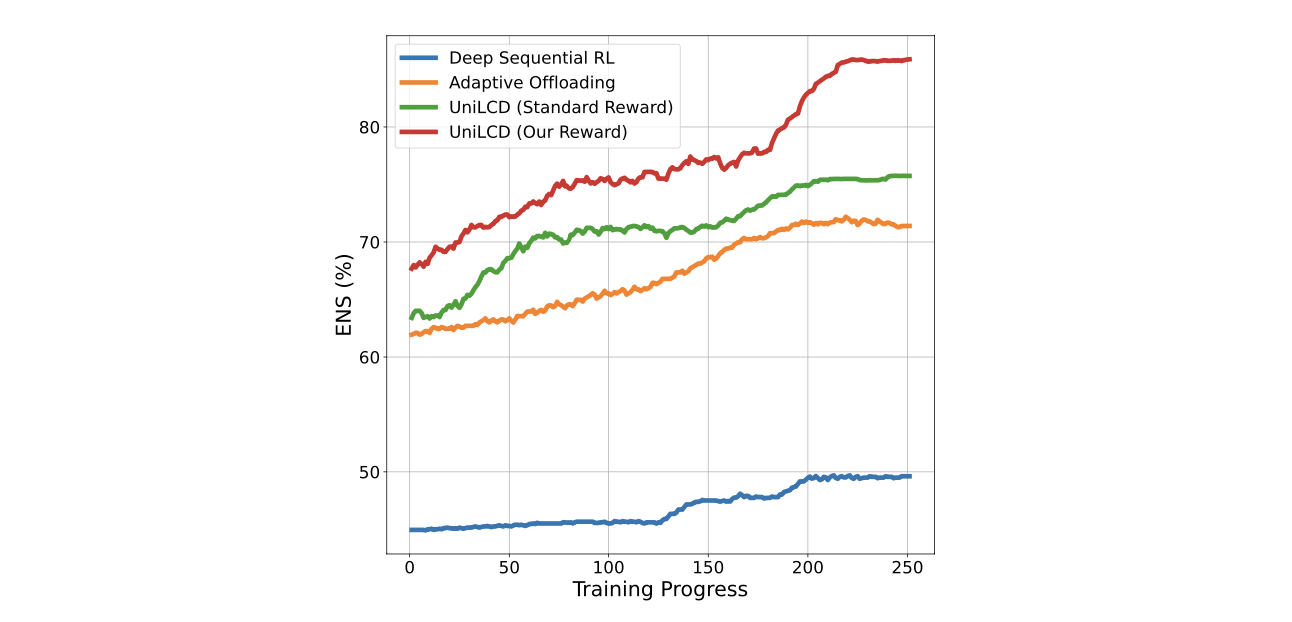
Result